
Unity使用C#解析与更新TXT、Json和XML文件

读取配置文件等对于一个游戏的重要性不需要多说,本文总结了本人最近经常用到的C#解析文本文件的方法。本文作为一个涂鸦,仅仅用于提供几个解决问题的思路,对于代码是否高雅等问题不予考虑。
准备工作
创建一个类,用于保存单个Site信息。
public class Site {
public string Name{get;set;}
public string Url{ get; set;}
}
创建一个类,用于保存Site类数组。
public class SitesList {
public Site[] sites;
}
创建一个脚本,名称随意,Start方法中写初始化路径代码(下文所提的初始内容即为此):
// Application.dataPath,unity中用来获取 Assets 路径的属性,仅用来举例测试。
string path = Application.dataPath + "/Resources/";
string jsonName = "Sites.json";
string txtName = "Sites.txt";
string xmlName = "Sites.xml";
string jsonPath = path + jsonName;
string txtPath = path + txtName;
string xmlPath = path + xmlName;
TXT文件的存储与解析
TXT保存
思路:将类手动转换成字符串,拼串,保存至文件中。 代码:
public void TxtToFile(SitesList sitesList,string filePath)
{
string str = "Name|Url" + '\n';
for (int i = 0; i < sitesList.sites.Length; i++) {
str += sitesList.sites[i].Name
+ '|'
+ sitesList.sites[i].Url
//最后一行不用追加换行
+ (i == sitesList.sites.Length - 1 ? "": "\n");
}
FileStream fs = File.Open (filePath, FileMode.Create);
StreamWriter sw = new StreamWriter (fs);
sw.Write (str);
sw.Flush ();
sw.Close ();
fs.Close ();
Debug.Log ("保存成功");
}
start中追加如下内容:
Site s1 = new Site (){ Name = "梓喵出没",Url ="http://www.azimiao.com"};
Site s2 = new Site (){ Name = "Xema", Url = "https://" };
Site s3 = new Site (){ Name ="Pret",Url = "https://"};
SitesList siteList = new SitesList ();
siteList.sites = new Site[]{ s1,s2,s3};
TxtToFile (siteList, txtPath);
unity中创建一个Cube(随意),将该脚本挂载到该游戏对象中,点击运行。 效果如图:
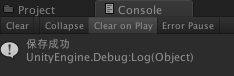
保存文件的内容为:
Name|Url
梓喵出没|http://www.azimiao.com
Xema|https://
Pret|https://
TXT读取与格式化
思路:读取文件中所有内容,按换行符号’\n’切割字符串,获取的字符串数组每个元素即为一个Site对象。按照标识符分隔对象字符串(这里使用的是’|’),创建对象分别赋值即可。 代码:
public void TxtToClass(out SitesList rec,string filePath)
{
rec = new SitesList ();
if (!File.Exists(filePath)) {
Debug.Log ("文件不存在");
return;
}
FileStream fs = File.Open (filePath, FileMode.Open);
StreamReader sr = new StreamReader (fs);
string txtData = sr.ReadToEnd ();
//切割每一行
string[] lineData = txtData.Split ('\n');
//容器内数组初始化
rec.sites = new Site[lineData.Length -1];
for (int i = 1; i < lineData.Length; i++) {
int index = 0;
//切割元素字符串
string[] siteTemp = lineData [i].Split ('|');
//给容器内数组赋值
rec.sites [i - 1] = new Site (){Name =siteTemp[index++],Url = siteTemp[index++] };
}
}
start中追加如下内容(初始内容追加,下同):
SitesList siteList = new SitesList ();
TxtToClass (out siteList, txtPath);
foreach (Site item in siteList.sites) {
Debug.Log (item.Name + "|" + item.Url);
}
运行结果: 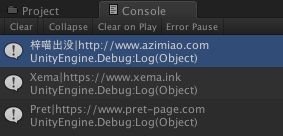
TXT更新
txt文件没有节点一说,也就没有修改某节点局部更新的方法,因此需要拼接新的字符串覆盖原内容。这与保存内容一致,因此不再重复。
JSON文件的存储与解析
额外准备工作:需要导入LitJSON.dll并引用其命名空间:
using LitJson;
JSON保存
思路:先将Site类格式化为Json字符串,然后检查文件是否存在(覆盖or创建),最后保存字符串。 代码:
//将类转化为Json对象
public void SiteToJson(SitesList siteList,string filePath)
{
string jsonData = JsonMapper.ToJson (siteList);
//可以不写,pen方法会根据参数自动处理
if (!File.Exists(filePath)) {
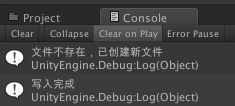
//文件不存在则创建新文件
FileStream fstemp = File.Create (filePath);
fstemp.Close ();
Debug.Log ("文件不存在,已创建新文件");
}
//打开文件流,Create模式表示如果不存在则创建,如果存在则覆盖原内容
FileStream fs = File.Open (filePath, FileMode.Create);
//创建StreamWriter
StreamWriter sw = new StreamWriter (fs,System.Text.Encoding.UTF8);
sw.Write (jsonData);
//清空缓冲区,确保写入
sw.Flush ();
//关闭StreamWriter
sw.Close ();
//关闭文件流
fs.Close ();
Debug.Log ("写入完成");
}
start中追加如下内容(初始内容追加,下同):
Site s1 = new Site (){ Name = "梓喵出没",Url ="http://www.azimiao.com"};
Site s2 = new Site (){ Name = "Xema", Url = "https://" };
Site s3 = new Site (){ Name ="Pret",Url = "https://"};
siteList.sites = new Site[]{ s1,s2,s3};
SiteToJson (siteList, jsonPath);
运行效果:
打开创建的Json文件,发现添加的内容为(原内容无换行,为了美观手动添加了换行):
{
"sites":
[
{"Name":"\u6893\u55B5\u51FA\u6CA1","Url":"http://www.azimiao.com"},
{"Name":"Xema","Url":"https://"},
{"Name":"Pret","Url":"https://"}
]
}
JSON读取与格式化
思路:先读取文件中所有字符,然后将其转化成Json字符串,最后将其解析为对象。 代码:
//将Json转化为类
public void ParseXml(out SitesList rec,string filePath)
{
if (!File.Exists(filePath)) {
Debug.LogWarning (filePath +"不存在");
return;
}
//FileMode.Open,打开已经存在的文件,如果不存在则抛出文件不存在异常
FileStream fs = File.Open (filePath,FileMode.Open);
StreamReader sr = new StreamReader (fs);
string data = sr.ReadToEnd ();
rec = JsonMapper.ToObject<SitesList> (data);
//关闭流
sr.Close ();
//关闭流
fs.Close ();
Debug.Log ("读取完成");
}
start中追加如下内容(初始内容追加,下同):
SitesList siteList;
ParseXml (out siteList, jsonPath);
foreach (Site item in siteList.sites) {
Debug.Log (item.Name+"|"+item.Url);
}
运行结果:

更新
不写,原因同TXT。
XML
Xml美滋滋美滋滋。 准备工作: 引用命名空间:
using System.Xml;
创建一个xml文件,包含xml头及根节点:
<?xml version="1.0" encoding="UTF-8" ?>
<Sites></Sites>
XML添加与保存
思路:获取xml根节点,向xml根节点插入子节点,最后保存即可。 代码:
public void ClassToXml(SitesList sitesList,string filePath)
{
XmlDocument doc = new XmlDocument ();
//加载文件
doc.Load (filePath);
//获取根节点Sites
XmlNode root = doc.SelectSingleNode ("Sites");
foreach (Site item in sitesList.sites) {
XmlElement site = doc.CreateElement("Site");
XmlElement name = doc.CreateElement ("Name");
name.InnerText = item.Name;
XmlElement url = doc.CreateElement ("Url");
url.InnerText = item.Url;
//添加子节点
site.AppendChild (name);
site.AppendChild (url);
root.AppendChild (site);
}
//保存文件
doc.Save (filePath);
}
start中追加如下内容(初始内容追加,下同):
Site s1 = new Site (){ Name = "梓喵出没",Url ="http://www.azimiao.com"};
Site s2 = new Site (){ Name = "Xema", Url = "https://" };
Site s3 = new Site (){ Name ="Pret",Url = "https://"};
SitesList siteList = new SitesList ();
siteList.sites = new Site[]{ s1,s2,s3};
ClassToXml(siteList,xmlPath);
运行结果: 打开原xml可见添加内容如下:

XML读取与解析
思路:获取根节点Sites,循环遍历根节点获取每个子节点Site,通过Site中的Name节点与Url节点的innerText创建对象。 代码:
public void XmlToClass(out SitesList rec, string filePath)
{
XmlDocument doc = new XmlDocument ();
doc.Load (filePath);
XmlNode root = doc.SelectSingleNode ("Sites");
XmlNodeList xmlSites = root.SelectNodes ("Site");
rec = new SitesList ();
rec.sites = new Site[xmlSites.Count];
int index = 0;
foreach (XmlNode item in xmlSites) {
string name = item ["Name"].InnerText;
string url = item ["Url"].InnerText;
Site temp = new Site (){ Name = name, Url = url };
rec.sites [index] = temp;
index++;
}
在Start中追加如下内容:
SitesList siteList = new SitesList ();
XmlToClass (out siteList, xmlPath);
foreach (Site item in siteList.sites) {
Debug.Log (item.Name + "|" + item.Url);
}
运行结果: 如下图所示: 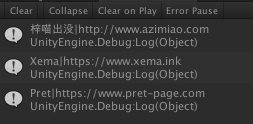
XML更新
思路:通过条件语句获取节点对象,修改innerText的值,最后保存即可。可通过上文略加修改实现。
XML删除某节点
使用doc.RemoveChild(XmlNode oldNode)即可。
总结
相对于TXT与JSON,XML更易实现局部更新。通过这几个小例子,能够掌握简单的文件读写即文件序列化与反序列化方法。
引用资料
- [头图]【Unity】Unity-Japan UnityChanSD角色
emmm 大大大大佬 那个邮件通知的插件一直发送失败怎么破呀?
哪个插件呢?
汪汪汪~ 加友链啦~
answer:www.traceback.cc
已加!
你 老司机 做游戏